Preword: This article is about failing runtime dependencies mostly in form of external (Web)API calls.
During the last weeks at work, I had to learn this the hard way: Dependencies are screwing you over and over again.
You may ask “why?” and for the reasons causing my bitter sentiment. In fact, they are basic. I am a developer of a backend powering an Android and an iOS App. Due to outages of our dependencies we are currently getting negative feedback. This negative feedback comes back in the form of single star reviews in the App Stores.
“But how can this happen?” you might be asking. For me, it is also hard to accept that it is currently that way. Personally, I identified a few reasons for our current issues:
We are not owning all the basic functionality
This didn’t come instantly to my mind. But often it is that something is failing for us (e.g. the login) or some middleware. We then can not anything effective against it but giving the responsible department a small nudge so that they can take actions. This is frustrating and not a good situation. Avoid this at any cost!
We depend on external data
Customers get identified, authenticated, configured and update their status on a 3rd party system. Also, many of our features are executed by 3rd party services.As long as they are up and running – everybody is happy. It feels as soon as some of them start to run into issues their issues are not isolated.
- No authentication – Sorry you can not access the app (for security reasons)
- Not able to retrieve the identity – Sorry we can not even show you basic stuff
- Not able to get your configuration – Sorry we can not figure out what to show to you … The list could go on.
*** “Hey, ever heard about SLAs?” Of course, we have. But sometimes it is:
- Hard to get them from an internal provider
- No use if they get periodically violated (especially from internal providers)SLAs, even ones with high availability, don’t protect you from having too many SOFs (Single point of failure). Having a single point of failure is a bad thing, I will show you why in a second.
The curse of having dependencies
Dan starts to create his App Backend. Dan is pretty confident that his uptime will be awesome. He talked to all the stakeholders and they negotiated with their service partners that all of the dependencies have an SLA of at least 99%. Dan is pumped during the first weeks of his newly released backend.
After a few days, Dan gets the first reviews of his customers: “Never works during peak hours” “I once urgently needed the App and it didn’t work” “Always feels sluggish when I use it during peak hours”Dan investigates.
What he finds out is leaving him in awe. When he has a look at his basic uptime monitoring his Backend is hovering around 90% which translate to a 2 hours and 30 minutes time window in which his services are not available (per day)!
These stats even ignore that it was not reachable for half of the release day. What a disaster!
The curse of dependencies
Coming back from our example it is simple math here. If each of your dependencies can cause an outage, all of the odds multiply. This gets worse the more dependencies you add to the mix.
Let’s say we have a Price comparison App which shows prices from different platforms. Dan was happy that he does not have to generate the data by itself and he gladly added all the data providers with their high availability.
What Dan did not have in mind is this simple formula for the overall probability of failure for N Single Point of failures:

If every SOF has the same availability the formula is getting easier:
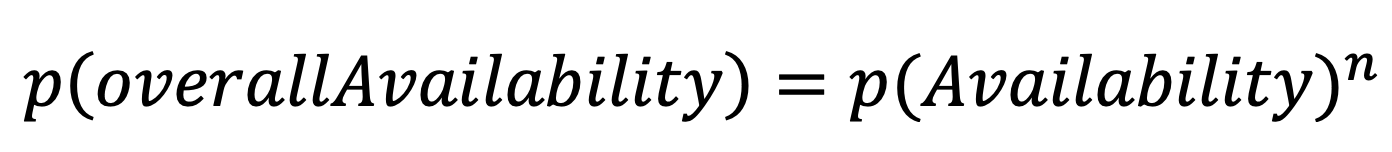
Coming back to the price comparison page:
Dan added 25 external service providers. These providers all have an SLA of at least 99%. With these numbers the expected uptime of Dan’s service would be: 0,99^25 = 77,8% – OUCH!
And this is not even counting in that services might just be a bit slow which can cause other issues. In practice this means that his expected downtime per day would be around 5 hours and 20 minutes.
As you can see the dependencies got him here – his service is not pleasant to use.
Who is to blame?
Maybe my opinion is not popular, but I would say Dan himself. During your design, you have to design for failure and partial failure.
Many times I heard “Hey we can not improve the reliability of other services!”. That’s right – but we can design how we deal with their failures.
Embrace Failure
“Your dependencies will FAIL!”
Keep this in mind and often you will not run in such issues. Often I see in practice that developers (for the notes: I am not excluding myself) tend to forget about the fallacies of distributed systems. Summing them up here:
- The network is reliable.
- Latency is zero.
- Bandwidth is infinite.
- The network is secure.
- Topology doesn’t change.
- There is one administrator.
- Transport cost is zero.
- The network is homogeneous.
If you design your system with these assumptions you are setup for issues when they are not met.
Kind of failures
We can group most of the issues with remote services in 3 categories:
- Depending service is not available (fails fast for all calls)
- Depending service is very slow and even times out (fails slowly for all calls)
- Only some calls to the depending service are slow (sporadic slowness of some calls)
- Under stress, the service is degrading and only giving you partial returns (not covered here)
What can be done to prevent such scenarios from happening?
I first give a list of possible approaches to then go into more detail for each category of failure:
- Not consider the response of that particular depending service
- Return the response from a cache
- Use aggressive timeouts in combination with a possible retry
- Fast failures
- Not consider the response of that particular depending service:
This is most of the time, when from a functional point of perspective possible a good idea. For Dan, this could mean that a service which is not available would not be in the price comparison. - Return the response from cache:
Also not bad, when a service is not available we will return a cached response for that query. Keep in mind that this may have legal consequences. Dan is not sure if he wants to show cheap prices when an item is already out of stock (because he has only cached information when the item was still on stock). - Use aggressive timeouts with retries:
Doesn’t make sense here, since the following calls will also fail. Timeouts are not needed since the service is already responding fast.
- Not consider the response of that particular depending service:
- Slow failures
- Not consider the response of that particular depending service: Same as for fast failures, when you implement this you realize that this has to be paired with timeouts. Timeouts are needed because otherwise, the slowness will populate to consumers of your own service.
- Return the response from a cache: Basically the same as for the fast failure, with the same necessity of pretty aggressive timeouts.
- Use aggressive timeouts with retries:
This is, in general, advisable when a user is waiting for the result of your operation. A few seconds may be enough for the user to lose interest and to walk away from your application. Retries are not worth it here since the retry will run into the same timeout.
- Sporadic slowness
- Pretty much the same as slow failures, just that the retry mechanic here is valuable because it will actually return a valid response in a short time window.
As you can see not each scenario is benefiting from the same measures. In general, it is advisable to have a reasonable timeout for your users to wait and also to provide some sort of caching to at least have something to fall back to.
Another possible way to migrate this issue altogether is to try to decouple the fetching of the data from the user interaction. Sadly this is not possible in all cases.
As an example: Dan could have used this mechanic to periodically fetch the currency conversion rates. This would be feasible because each request to the API probably looks the same and the response could maybe contain all currency pairs. This overall would reduce a lot of flakiness and in case something goes wrong, the cache probably still has an old response stored.
“Hey, so timeout all the things. Right?”
It is not that simple. What I also had to learn is that often a timeout might not be sufficient. During one of our recent downtimes, we could see that one of our services overflowed with requests and started crashing despite having a timeout of 5s.
What happened there? It seemed that the incoming traffic was piling up in the services and then they eventually ran out of threads. The problem was that the incoming requests were choking on the thread pool of the outgoing HTTP client. In other words, requests came in faster than the services were able to get rid of them.
“Well but 5s seems really reasonable …”
Of course, it does 🙂 But sometimes it is not enough. What else could be done?
Right after reading about it, I became a fan of the circuit breaker pattern.
What is a circuit breaker?
You might know circuit breakers from your own household. They are protecting your wires and electronic devices from being exposed to excess current from overloads or short circuit. The same principle applies to the circuit pattern.
When a service fails or is slow (beyond timeout), the calling service backs down and stops calling the real service. Instead, it is handling it in a fast failing way and providing a possible callback. In the meantime, the service probes whether the dependency is again available with single requests. When these probes come back with successful results, the circuit is closed again and all the calls arrive at the target.
This pattern is great to handle problems caused by slow failures – another good side-effect here is, that it is giving your depending service a bit of breathing room to recover.
Recap
Speaking from experience: Developers (yes – even myself included) make wrong assumptions about reliability of different dependencies. You always should keep in mind that things which are able to fail will eventually do so.
Thinking about the failure of other systems is often underrated or even forgotten. Since the availability of your service is something you should really care about, it is your duty to ensure it even when other things break.
My advice is to more often think “What happens if this thing is failing or slow?”. Your users will thank you a thousand times!
I would really like to hear your opinion and experience within this topic. Feel free to contact me on twitter to start a discussion.
About the Author:
