Do you know that feeling? You have a webservice dependency which is not having the best uptime? My team at work certainly has, and thought that it was time for a change.
This whole article is written as a tutorial. You can find the code on the GitHub Repository.
Status Quo and Evolution:
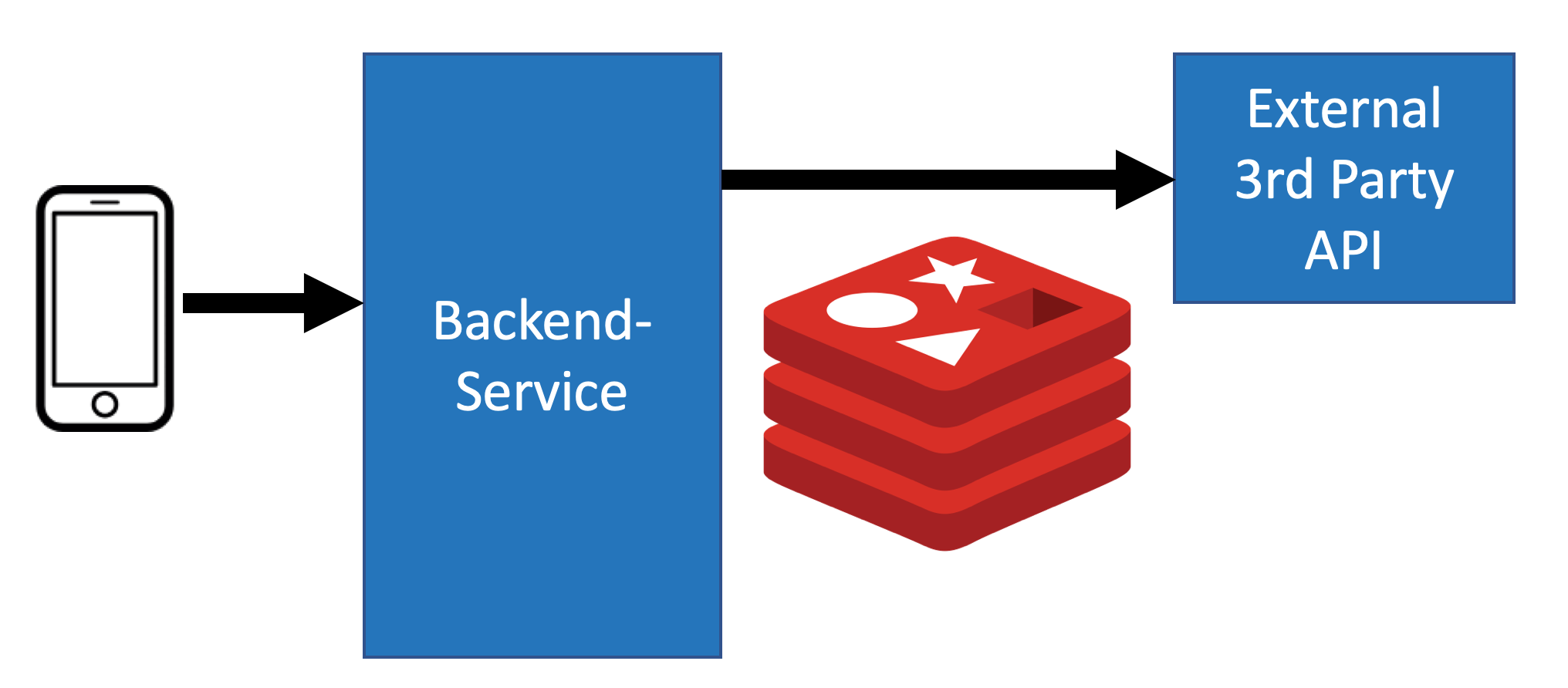
As depicted in this chart, we are having an Android and an iOS app which access our backend services. Exemplary for our total backend, I have drawn one service. As you can see it is already using Redis as a Cache for our HTTP response. This cache is there so that we do not make too many requests to our 3rd party service. If you are interested in this setup you might find my article ‘Spring Boot Redis: Ultimate Guide to Redis Cache with Spring Boot 2‘ really interesting. It is exactly about building this scenario.
Technically all of this is done via Spring Cache. It is leveraging the support of Spring Boot for Redis as a Cache Manager. Running with this setup we are able to annotate on method level which methods should be getting cached. All of this can be based on the method parameters passed, if you provide a generated key.
When creating different caches for each method we are even able to provide different TTLs for each method getting cached. If you are interested in this kind of setup, I am going to write a tutorial explaining exactly how to set this up. I will put a link here once it is finished.
For a long time this made us really happy. We could greatly reduce the amount of HTTP calls we were making and also could greatly improve our response times since Redis is much faster than doing HTTP calls to a remote 3rd party provider – and they lived happily ever after
Relationship Crisis: When it started to go downhill
So our caching worked pretty well. We had a sensible time-to-live (TTL) of one hour which matched our use case.
But what did happen then?
On one day, the 3rd party provider was down. We also were not in a good shape since we did not prepare for this issue.
First draft for the win: Just replace every failed request from the service with an empty response and cache that.
The services were performing again. BUT: In some cases the users were missing data or even worse were not getting any data at all. This was not optimal.
What else could be done to prevent outages when the 3rd party services is away? We increased the caching time significantly. We upped it to 2 hours, 4 hours or even 8 hours. This helped us in the face of longer outages we had to survive.
Sadly this measure came with a price: All the time a returning user was seeing old data – up to 8 hours old. If his state on the 3rd party system changed, it took us up to 8 hours to reflect the change – ouch!
So looking back: This helped against the downtimes, but the time it took us to update the information was just not bearable. There had to be a better way. This is when the idea struck us:
Why don’t we run with two layers of caching?
A two layer cache: A cache which has a long TTL but starts already to refresh its entries before they expire. In case of a downtime, the entries will still be there (as long as the downtime is not exceeding the TTL or we have a cache miss).
Genius! We could use a, lets call it, “firstLayerTtl” of 1 hour and a “secondLayerTtl” in which an entry is kept but not used for serving user requests.
Awesome, but how would we implement it within our Spring Boot Application? Writing custom stuff with templates in each method is not really cool.
For us it was clear it should be more or less a drop-in replacement for the @Cacheable Annotation. During my Spring Certification I came along Aspect Oriented Programming (AOP) which was able to being wrapped around methods and do a lot of advanced things within Spring.
Spring AOP
How could it fit here?
If you are not yet familiar with AOP better have a look over at the official Spring Framework Reference: AOP and also https://www.baeldung.com/spring-aop-annotation. The second one is especially valuable since there you are using an Around Advice to log execution time of a method.
Trying to explain it easy: AOP allows you to create some sort of condition (PointCut) which tell the container on which things you want to apply your logic. Then you have your Advice which is saying the container what you want to do in case you come across such a method.
Lets take the final example of baeldung.com here:
@Around("@annotation(LogExecutionTime)")
public Object logExecutionTime(ProceedingJoinPoint joinPoint) throws Throwable {
long start = System.currentTimeMillis();
Object proceed = joinPoint.proceed();
long executionTime = System.currentTimeMillis() - start;
System.out.println(joinPoint.getSignature() + " executed in " + executionTime
+ "ms");
return proceed;
}
When you have a look at the @Around annotation here you can already think what it should do: It is targeting all methods which are annotated by “@LogExecutionTime” which is a custom annotation. Also it should be visible that the logic is placed around the real method invocation.
In detail this logic here is taking the currentTimeMillis before and after the method invocation and logging the difference via System.out.println.
Pretty easy, pretty straight forward. If you want to use this logic on some of your methods, you just have to annotate them with @LogExecutionTime. That was a working example of AOP in a nutshell.
How does this fit our requirement?
Well, we also want to check if our cache is containing a specific entry before calling the real method. This can easily be done with the Around Advice.
But what is the exact requirement?
Let’s have a look at the @Cacheable Annotation or especially how we use it at work. Here is an example on how we annotate some methods:
@Cacheable(cacheNames = "MyFirstCache", key = "'somePrefix_'.concat(#param1)")
public SomeDTO getThirdPartyApi(String param1) {
getDataViaHTTP(param1);
}
As you can see it is not too hard to specify dynamic keys. We use the Spring Expression Language (SpEL) to generate our keys during runtime. We more or less wanted to have the same semantic for our two layer Caching solution as with the @Cacheable Annotation. Since we were aiming for the exact same syntax with additional parameters, we went with the following format:
@TwoLayerRedisCacheable(firstLayerTtl = 1L, secondLayerTtl = 5L,
key = "'somePrefix_'.concat(#param1)")
public SomeDTO getThirdPartyApi(String param1) {
getDataViaHTTP(param1);
}
The implementation
To be totally honest, the hardest part for me was to figure out how to get the dynamic parameters inside the Advice. But one step after the other:
What we need:
- An annotation which is called TwoLayerRedisCacheable with our parameters firstLayerTtl, secondLayerTtl and a dynamic key attribute.
- A Pointcut wiring the use of our Annotation to the execution of our Advice Logic
- An Around Advice which reads the parameters of the annotation and interacts with Redis accordingly
The logic for interacting with Redis is quickly sketched in the following pseudo-code:
Check if a key is available in Redis:
YES (Cache Hit):
Check if the firstLayerTtl already passed by
YES (Entry is in 2nd Layer Cache):
Try to call the real method
On Success:
Store the new result with a proper TTL
On Failure:
Extend the existing TTL to put it back into the first layer and
return the result
NO (Cache Entry is still in first layer): Return the response from Redis.
NO (Cache miss):
Call the method and store the result in Redis
Lets get it started
Reminder: The whole final source code is available at my GitHub Repository.
Lets first create our Annotation:
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface TwoLayerRedisCacheable {
long firstLayerTtl() default 10L;
long secondLayerTtl() default 60L;
String key();
}
Cool, that was easy. How would an example class using this look like?
@Service
public class OrderService {
@TwoLayerRedisCacheable(firstLayerTtl = 1L, secondLayerTtl = 5L, key =
"'orders_'.concat(#id).concat(#another)")
public Order getOrder(int id, String other, String another) {
//in reality this call is really expensive and error-prone - trust me!
return new Order(id, Math.round(Math.random() * 100000));
}
}
Now we have a method which is using our annotation and also the annotation itself.
Next step will be creating the Aspect. Let’s call it: TwoLayerRedisCacheableAspect.
The Aspect
@Aspect
@Component
@Slf4j //this is a lombok Annotation to get a Slf4j logger
public class TwoLayerRedisCacheableAspect {}
Time to write our Pointcut inside our just created Aspect-Class:
@Pointcut("@annotation(twoLayerRedisCacheable)")
public void TwoLayerRedisRedisCacheablePointcut(
TwoLayerRedisCacheable twoLayerRedisCacheable) {}
The Pointcut tells the container to look for methods annotated with our TwoLayerRedisCacheable annotation – exactly what we want!
The Advice
The last remaining step now is writing the AroundAdvice and bring it to life by extracting the parameters from the JoinPoint (the actual invocation of our guarded method) and the interaction with Redis.
First things first: Lets extract the parameters from the JoinPoint. Don’t be embarrassed it took me quite a while and finally needed support from StackOverflow to finally figure it out.
The logic for extracting the parameters is a bit more complicated:
- Extract all static parameters from the annotation
- Create a SpelExpressionParser which should be re-used between invocations
- For each invocation: Create a context, which needs to be populate with the parameters of the call
For me this resulted in having three methods and a static field:
private static final ExpressionParser expressionParser = new SpelExpressionParser();
@Around("TwoLayerRedisRedisCacheablePointcut(twoLayerRedisCacheable)")
public Object cacheTwoLayered(ProceedingJoinPoint joinPoint,
TwoLayerRedisCacheable twoLayerRedisCacheable)
throws Throwable {
long ttl = twoLayerRedisCacheable.firstLayerTtl();
long grace = twoLayerRedisCacheable.secondLayerTtl();
String key = twoLayerRedisCacheable.key();
StandardEvaluationContext context = getContextContainingArguments(joinPoint);
String cacheKey = getCacheKeyFromAnnotationKeyValue(context, key);
log.info("### Cache key: {}", cacheKey);
return joinPoint.proceed();
}
private StandardEvaluationContext
getContextContainingArguments(ProceedingJoinPoint joinPoint) {
StandardEvaluationContext context = new StandardEvaluationContext();
CodeSignature codeSignature = (CodeSignature) joinPoint.getSignature();
String[] parameterNames = codeSignature.getParameterNames();
Object[] args = joinPoint.getArgs();
for (int i = 0; i < parameterNames.length; i++) {
context.setVariable(parameterNames[i], args[i]);
}
return context;
}
private String getCacheKeyFromAnnotationKeyValue(StandardEvaluationContext
context,
String key) {
Expression expression = expressionParser.parseExpression(key);
return (String) expression.getValue(context);
}
In its current state the method would just log the generated CacheKey and afterwards call the original method. So far so good. Time to add the real logic.
In order to access Redis, we first need to do some configuration. This configuration here might be a bit overkill for a simple working example. I have chosen this route since we have a similar configuration at my workplace and I definitely wanted to use it there.
The Configuration of Redis
@Configuration
@EnableCaching
@EnableConfigurationProperties(CacheConfigurationProperties.class)
@Slf4j
public class TwoLayerRedisCacheLocalConfig extends CachingConfigurerSupport {
@Bean
public JedisConnectionFactory redisConnectionFactory(
CacheConfigurationProperties properties) {
JedisConnectionFactory redisConnectionFactory = new
JedisConnectionFactory();
redisConnectionFactory.setHostName(properties.getRedisHost());
redisConnectionFactory.setPort(properties.getRedisPort());
return redisConnectionFactory;
}
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory cf)
{
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(cf);
return redisTemplate;
}
@Bean
public CacheManager cacheManager(RedisTemplate redisTemplate) {
return new RedisCacheManager(redisTemplate);
}
}
As you might have realized there is a reference to some CacheConfigurationProperties. This is the content of the file which is used to provide the host and port for our connection to Redis:
@ConfigurationProperties(prefix = "cache")
@Data
public class CacheConfigurationProperties {
private int redisPort = 6379;
private String redisHost = "localhost";
}
Coming back to the Aspect
Lets get started on the real implementation and switch back to our Aspect. There we create a field which we inject using constructor injection. Therefore we create a field And inject it using the constructor:
private Map templates;
public TwoLayerRedisCacheableAspect(Map redisTemplateMap) {
this.templates = redisTemplateMap;
}
Now we got all the building pieces and can start to mess around in the Around-Advice. Here is my first result:
@Around("TwoLayerRedisRedisCacheablePointcut(twoLayerRedisCacheable)")
public Object clevercache(ProceedingJoinPoint joinPoint,
TwoLayerRedisCacheable twoLayerRedisCacheable)
throws Throwable {
long firstLayerTtl = twoLayerRedisCacheable.firstLayerTtl();
long secondLayerTtl = twoLayerRedisCacheable.secondLayerTtl();
String key = twoLayerRedisCacheable.key();
String redisTemplateName = twoLayerRedisCacheable.redisTemplate();
StandardEvaluationContext context =
getContextContainingArguments(joinPoint);
String cacheKey = getCacheKeyFromAnnotationKeyValue(context, key);
log.info("### Cache key: {}", cacheKey);
long start = System.currentTimeMillis();
RedisTemplate redisTemplate = templates.get(redisTemplateName);
Object result;
if (redisTemplate.hasKey(cacheKey)) {
result = redisTemplate.opsForValue().get(cacheKey);
log.info("Reading from cache ..." + result.toString());
if (redisTemplate.getExpire(cacheKey, TimeUnit.MINUTES) < secondLayerTtl)
{
log.info("Entry passed firstLevel period - trying to refresh it");
try {
result = joinPoint.proceed();
redisTemplate.opsForValue().set(cacheKey, result, secondLayerTtl
+ firstLayerTtl, TimeUnit.MINUTES);
log.info("Fetch was successful - new value was saved and is
getting returned");
} catch (Exception e) {
log.warn("An error occured while trying to refresh the value -
extending the existing one", e);
redisTemplate.opsForValue().getOperations().expire(cacheKey,
secondLayerTtl + firstLayerTtl, TimeUnit.MINUTES);
}
}
} else {
result = joinPoint.proceed();
log.info("Cache miss: Called original method");
redisTemplate.opsForValue().set(cacheKey, result, firstLayerTtl +
secondLayerTtl, TimeUnit.MINUTES);
}
long executionTime = System.currentTimeMillis() - start;
log.info("{} executed in {} ms", joinPoint.getSignature(), executionTime);
log.info("Result: {}", result);
return result;
}
The implementation here is doing is exactly what we talked about earlier in our Pseudocode. It is trying to use an existing entry, if it is there and it is still fresh. When an entry is older than the first layer, it is trying to update it and set the new version in the cache. In case of failure, we just return the old value and extend its TTL. When there is nothing in the Cache, we just return invoke the method and store the result in the Cache, here we propagate every exception to make our caching transparent to the user.
Let’s Test It!
In the end, I created a small controller, so that we are able to try our implementation using a REST Endpoint:
@RestController
@AllArgsConstructor
public class ExampleController {
private OrderService orderService;
@GetMapping(value = "/")
public Order getOrder() {
//hardcoded to make call easier
int orderNumber = 42;
return orderService.getOrder(orderNumber, "Test", "CacheSuffix");
}
}
Keep in mind: When we use the current implementation it is not failing at all. When you want to try it you can build in a random fail mechanism (e.g. throw an exception 90% of the times).
When we inspect our Redis using redis-cli we can inspect the TTLs set by our implementation:
When we inspect our Redis using redis-cli:
± redis-cli -h 127.0.0.1 -p 6379
KEYS * (to see all keys)
TTL SOME_KEY (to see the real TTL on redis)
In case we added some random failure, we still can see how our Application is able to refresh the TTL even tough the implementation itself is not able to fetch the data. Your App would survive an outage of a 3rd Party API.
Really awesome!
Outlook
On paper this looks perfect. But there are a few holes and things to consider. Raising the overall TTL definitely increase RAM consumption on Redis which can be quite problematic for the overall behaviour of the system, even when using eviction.
Also this approach is not guarding us against SLOW responses. Sadly slow responses would still cause us issues, since our refreshes still would try to hit the 3rd party service and then take a long time. This issue could be tackled by introducing a circuit breaker pattern on top of this approach. Since this post is already long enough, I guess we will tackle this issue another time. If you made it until here, I am really proud of you.
If you are running into any issues, have a look again at the GitHub Repository and feel free to reach out to me in case you have any questions. Would really love to hear your feedback on our approach.
About the Author:
